







(※並列にできるのは整数型、float型の四則演算のみです。命令や関数の並列処理は難or不可です。)
前にブログに書いたようにhgimg3やHSPDXfixなどのプラグインは標準命令と比べて描画がとても早い。
標準命令ではスペックに限界があり、例えば自分の作りたいシューティングゲームなどがとても60FPS出せない場合はこれらのプラグインを使うと解決されることが多い。
たいていこういうプラグインは、ハードウェアに処理をさせているため高速に描画できます、とか書いてある。

その「ハードウェア」ってのはつまるところGPU(広義のグラフィックボードやビデオカード)のことで、端的に言えばこいつもCPUみたく四則演算ができる演算装置だ。ただCPUみたく高度な処理はきなくて、全画面のピクセルの書き換えとか、同時に何万もの同じ処理をしたいときなどに向いているとされている。
GPUは本来グラフィック関連の処理に特化されたチップなので、その用途以外で使われることは考えられていなかったようなのだが、GPGPUと言って最近このGPUがCPUにかわって様々な処理をするようになってきた。 動画変換や計算科学(流体力学やブラックホールシミュレーションなど)といった、グラフィックに関係ないところに使われるようになってきて、それもまたCPUで処理するより何十、何百倍も早いそうなのだ。
http://dic.nicovideo.jp/a/gpgpu (ニコニコ大百科がまとまってて分かりやすい!)
後にも書くが、流体力学の計算をCPUとGPUでやらせたときの処理時間比が私のパソコンでは最大180倍になるという結果になった!
これは2^n×2^nの計算領域でCPUとGPUで流体計算させたときの1ループの処理時間(秒)
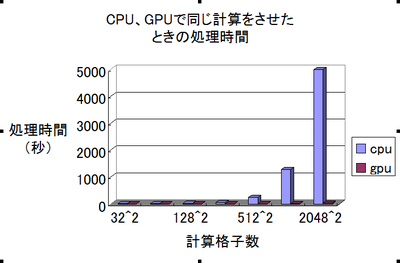
あまりにもGPUの計算時間が早くて、いまいちすごさがパッとしないので処理時間の比をとってみた
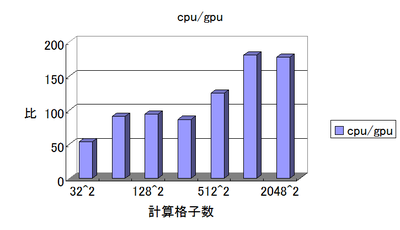
横軸が若干省略されてしまっているが、
512^2と2048^2の間にある1024^2の計算格子領域で一番GPU/CPU比が高く181倍も高速化ができた。
大岡山に存在するとされている某スパコンは、主にこのGPUで計算させているのでCPUのみのスパコンと比べすごく演算が早いとのこと。(もしCPUだけで同じ性能にしようとすると莫大なお金がかかる)
周波数が高いわけではなく、何万もの計算を並列に行なえるから結果的に早いのだそうだ。
・・・さて長い前置きは置いておいて、 私はHSPコンテストで分子シミュレーター
とか
重力シミュレーター

とか
まぁ普通にくだらないクソソフトを毎年量産しては応募しているのだが・・・
何がクソかというと、なんといっても処理が重いのだ!
これはプログラムが非効率なのもあるが、多数の粒子や相互作用などを計算すること自体がそもそも物理的に膨大な計算量を必要とする。
非力な私のノーパソのCPUでは、一億桁×一億桁の計算に何日もかかるというのに、分子のシミュレーションをリアルタイムでやろうとするなんぞ分不相応というか背伸びのしすぎであった・・・
今よりもCPUの性能が上がればいいのだが、生憎CPUのクロック数はもう頭打ちと言われていてせいぜい3.6Ghzが一般CPUの限界だから、今の1.5倍にしかならない。
HSPはマルチスレッド対応ではないため、私のやりたいシミュレーション系のプログラムはもうCPUだけでは限界なのだ。 多重起動の擬似マルチスレッド化とかして工夫はしてきたものやはりCPUに頼っているだけでは根本解決にはならない
そこで、本格的にGPGPUプログラミングに手を出そうと考えていた。
調べていくうちにGPGPUプログラミングのためにはnVIDIA製のGPU搭載デスクトップPCを買い、CUDAを勉強するのが一番手っ取り早いということがわかったのだが・・・
1 買う金がない
2 デスクトップ置く場所がない
3 CUDAを勉強する時間がない
の理由から諦めかけていた。
HSPでGPGPUプログラムができれば全て解決んだけど・・と思って何気なくHSPのサンプルを眺めていたら・・ これはもしかしたら、 HSPでGPGPUぽいことができるんじゃないのかと、そんな確信に近いある予感がひらめいた!!
きっかけはeasy3Dのサンプルのe3dhsp3_CbCr.hspを見た時だった
実行してみると、左には普通の3Dモデルのサンプルがリアルタイムで動いていて、右にはそのモデルの色だけがセピア色に変換されて同じく動いている

そうセピア変換とは、昔私がブログに無駄に長いソースを貼っつけたアレである。
まず画面の全ドットのrgb成分をyuvに逐一変換してuvに一定値を代入してまたrgbに変換・・・というやつである。
これをeasy3Dの中で実現しているということは、GPUにrgbをyuvに変換する並列処理をさせているということに他ならない!(CPUでリアルタイムなんかまず無理であろうし)
ということはソースかdllのプログラムのどこかにこのrgb成分をyuv成分に変換する、掛け、割り、足し、引きの計算式が書かれているはずだ!
そこのソースを改変すれば、自分の好きな手順、順番で四則演算ができるということではないのか!? この仮説が正しければeasy3Dのプラグインを使って高速並列計算が可能ということになる!
高速シミュレーションの道を開くために、執念でdllを解析しようかとか考えていたら、思いのほかもっと近くにその四則演算部分のプログラムを発見した
e3dhsp3.dllのと同じフォルダにある「E3D_HLSL」だ!

そのフォルダにposteffect.fxが入っていて、こいつがセピア変換の四則演算を記述してあるソースだった。
調べたらこの.fxという第二のソースはHLSLといってHigh Level Shader Languageというもうひとつの言語らしい
おや、fxファイルをメモ帳で開くとプログラムソースが見れる!
ということは編集もできるではないか!?
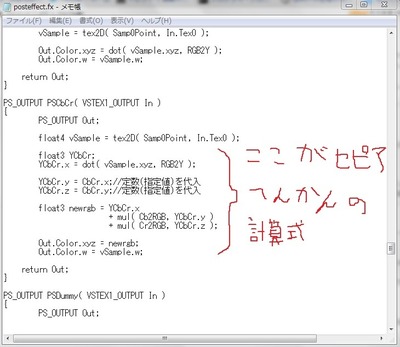
このファイルに自分で式を打って正常に動けば、自分の思い通りの並列処理が可能ってこと!?
試しに計算式を消したり追加したり実験してみたところ、コンパイルが正常に行なわれた
驚くべきことに、HSPで並列処理ができることがこれでわかった!!(正確にはHLSLでだけど・・・)
さらに驚くべきことに、easy3Dのソースを調べていくと律儀にも、私みたいなユーザーがposteffect.fxを改変できるようにと、なんとすでにカスタム領域が備わっていたのだ!
あとからおちゃっこさんのブログを見てわかったのだが「カスタムHLSL機能の需要は?」という名目で2年以上も前にこの自由に定義できるカスタムHLSLの機能を作っていたらしい。
つまりHSP側で並列計算させたいデータをeasy3Dの命令でGPUに送り、GPU側の処理の操作はHLSL(posteffect.fx)のカスタム領域で自分の好きな処理をさせられ、処理結果をまたHSP側で取り出すといった一連の操作が、我々ユーザーのためにすでに可能にされていたということだ。
HLSLのカスタムを可能にしてくれたおちゃっこさんには本当に感謝しないといけない!!
おちゃっこさんは需要なさそうと気にしていらっしゃったようだけど、これぞまさに私の求めていたもの!
この機能に出会えて本当に良かった!
HSPで並列演算ができるとわかった今、シミュレーションプログラムの幅が大きく広がること間違いなしである!!
これでもう数値解析やシミュレーションのデバッグに何日もかけないで済む!
HSPコンテストに糞ソフトと呼ばれるような生半可なシミュレーションソフトは出さないぞ。(呼んでいるのは主に自分)
さらにさらに驚くべきことに自分の非力なノーパにもそれなりのGPU・・オンボードだが・・がそなわっていたらしい!

今の今まで気づかなかった・・そもそもGPUなんて付いてないものかと・・
最大単精度浮動小数点バッファまで対応してるみたいだし、シェーダモデル4.0で、なんだか考えられる中で最高の環境が気づかぬ間に手元にそろっていたようだ。
で、 具体的な並列処理の方法だが、自分の手順をさかのぼってみて、例をおりまぜてまとめてみた。
まずHSP3.2は入っている前提で
・easy3dのサイトからEasy3DForHSP3_ver5233をダウンロードする
・解凍してreadme読む ・readmeの言われたとおりにする
・次に解凍した中のE3D_HLSLのフォルダもhsp3フォルダにコピー
・下のリンクからダウンロードしてきたposteffect.fxを、hsp3フォルダのE3D_HLSLの中にあるposteffect.fxに上書き
いきなりHLSLを自分でカスタムするのは難しいので、他人のカスタムしたものを参考に少しづつ変えて勉強していくのが一番いいだろう。またHLSLのサイトにいけば命令とか演算子が全部見られる。
サンプル 上のサンプルは、左の2枚の画像を加算、減算、割り算、掛け算しその結果を右に出力するというものだ。1~8のキー操作を受け付けて8種類の処理が見れるようになっている。

話を戻して、例えば足し算の並列演算をしたい場合なら、
・#include "e3dhsp3.as"して、E3DCreateRenderTargetTextureで、足す方を格納する2枚のテクスチャと、足した結果を出力するためのテクスチャをひとつ、合計3つ、同じ大きさで作る。
ようはc=a+bという計算をさせたい場合、aというテクスチャとbというテクスチャとcというテクスチャを作ってください、ということだ。
テクスチャの大きさは、並列に処理したい要素数によって変わってくる。65536要素の計算を並列に処理したいときは256*256の大きさのテクスチャをつくればいい。
・E3DShaderConstUserTexで足す2枚のテクスチャをGPUに送る
・E3DCallUserShaderでshadernoを0、passnoを1にして、足し算実行。これでE3DCallUserShaderの描画先のスワップチェインID(テクスチャ)に足し算結果が出力される。(ここらへんはサンプルの中にソースあり)
といった流れが、足し算の並列処理の方法だ。
passnoを変えれば割り算などを指定できる。
当然posteffect.fxを書き換えれば3つ4つ連続の足し算や、割った余りを求めるものなど、無限の処理が可能となる。
出力された計算結果(テクスチャ)はE3DShaderConstUserTexで指定しE3DCallUserShaderでつぎの処理に使いまわしていく事ができる。
上のスクリーンショットにも書いたが、E3DCreateRenderTargetTextureで作成するテクスチャのbit数を16bitや32bitにすれば、浮動小数点同士の足し算掛け算を並列処理できることとなる。
問題は、並列処理するときのデータが全てテクスチャ形式で行なわれているという点である。
はっきりいってHSP側で作ったDOUBLE型の配列変数を浮動小数点テクスチャに変換するというのはかなり至難の業である。(整数テクスチャならば話は簡単で、bmp形式でデータのやりとりを行なえばよい。)
というのもE3DCreateRenderTargetTextureで作ったテクスチャに1ドットずつ特定の値を書き込む命令がない。(というかeasy3Dはおそらくこの使いかたは想定していなかった)。だから何らかの方法で工夫しないといけないのだ。
それに、作れるテクスチャの精度が最大32bitなので標準命令のdoble型(64bit)と比べ精度が落ちる。グラフィックチップによっては16bitが限界だったりするから、CPUでのdoble型の計算をGPUで精度を落とさずやるには、16bitを4回計算みたいな感じでやるなどさらなる工夫が必要となる。
そして浮動小数点テクスチャから配列変数に戻すのも同様に大変である。
そこらへんを考慮した設計でないと、予想と結果が大きく異なってしまう可能性がある。
ということは、HSP側で配列変数を作る必要は本当にあるのかという疑問がわく。
並列演算出力結果を例えば視覚的に見るだけで良い場合(流体解析や分子動力学など)なら、posteffect.fx内で可視化プログラムを作ってしまえば、easy3Dのテクスチャレンダリング命令でスクリーンにいっきに可視化できる。わざわざHSP側で作った配列変数に値を戻さなくても、だ。
理想はそのような形で、最初から最後までテクスチャとして数値を保存しておく方が楽で良いのだが、厳密な数値を文字列として出力しなければいけないなど、どうしてもHSP側の変数に数値を戻す作業が欠かせない場合がでてくるだろう。 浮動小数点バッファを小数のまま保存できたりHSPのメモリに転送できる命令があればいいが、ない以上、1枚の浮動小数点バッファを何枚ものbmpに情報を分解して保存するアルゴリズムを構築するしかないのかもしれない。少なくとも私のお思いつく方法は今のとこそれしかない・・・
それだけがHSPでの並列処理においての大きな問題である。逆にもし単精度浮動小数点テクスチャと標準命令のdouble変数が両方向に対して変換可能になれば、まぁ64→32bitで精度が悪くなるのは仕方ないとして、タイトル通りの「HSPで高速並列演算」が可能になるというわけだ。これからは浮動小数点の構造の勉強をしてなんとか数値の取り込み、取り出しの問題を解決していきたいと思う・・・。
最後に、標準命令だけで作った流体力学プログラムを、HLSLに移植して並列処理化してみた。 計算は32bit浮動小数点バッファを使用、格子数は256*256で、CPUの80倍以上高速に処理できた。
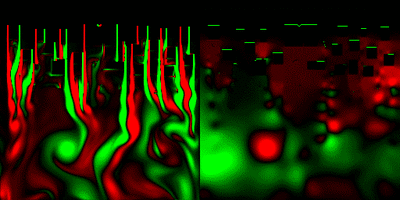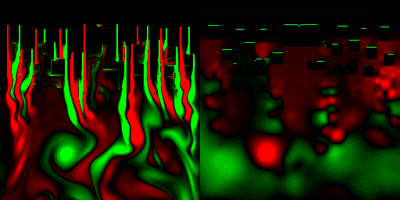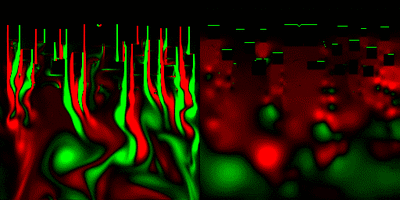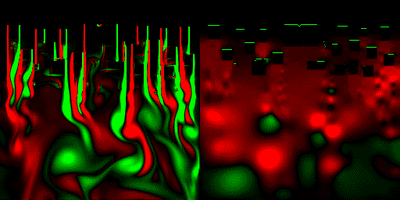
(一応解説すると、上から流体が流れてきてて、画面上の方にあるみにくいけど黒い動かないのが障害物。画面右は圧力を可視化した物。緑=高圧、赤=低圧)
これは、出力がスクリーンのみなので、posteffect.fxのほうに可視化プログラムが記述されており、可視化したテクスチャをeasy3DのE3DRenderSpriteでスクリーンにコピーしている、といったところ。
また入力のほうは、障害物の場所情報とか、0(なし) 1(あり) の2進数で表せるような情報しかないため、HSP側でbmpの生成→easy3Dでbmpの読み込み、bmpをスプライト(整数)に貼りつけ→32bit浮動小数点テクスチャにスプライト貼りつけ、・・と、数値の劣化なくGPUに送ることが出来ている。
並列処理を利用した数値解析シミュレーション特に流体力学はHSPコンテスト2011に向けて温めているもののひとつなのでネタバレはこのくらいにしておくとしよう。
次回:流体力学のプログラムを作りたい!その1
追記
HSP→浮動小数点バッファ への32bit浮動小数のデータ転送は
userFL4_0 ~ userFL4_9 のユーザー定義定数を使って正確に 行なえることが分かった。
また32bit浮動小数点を、4つの8bit*3(r,g,b)バッファに分解して転送して、HLSL側で数値を復元する方法も試みたが、仮数部の最小1bit部分でたまに誤差が生まれる模様・・・
また浮動小数データの分割&整数値化による GPUバッファ→HSP へのデータ転送は全くうまくいかず・・・orz
前にブログに書いたようにhgimg3やHSPDXfixなどのプラグインは標準命令と比べて描画がとても早い。
標準命令ではスペックに限界があり、例えば自分の作りたいシューティングゲームなどがとても60FPS出せない場合はこれらのプラグインを使うと解決されることが多い。
たいていこういうプラグインは、ハードウェアに処理をさせているため高速に描画できます、とか書いてある。
その「ハードウェア」ってのはつまるところGPU(広義のグラフィックボードやビデオカード)のことで、端的に言えばこいつもCPUみたく四則演算ができる演算装置だ。ただCPUみたく高度な処理はきなくて、全画面のピクセルの書き換えとか、同時に何万もの同じ処理をしたいときなどに向いているとされている。
GPUは本来グラフィック関連の処理に特化されたチップなので、その用途以外で使われることは考えられていなかったようなのだが、GPGPUと言って最近このGPUがCPUにかわって様々な処理をするようになってきた。 動画変換や計算科学(流体力学やブラックホールシミュレーションなど)といった、グラフィックに関係ないところに使われるようになってきて、それもまたCPUで処理するより何十、何百倍も早いそうなのだ。
http://dic.nicovideo.jp/a/gpgpu (ニコニコ大百科がまとまってて分かりやすい!)
後にも書くが、流体力学の計算をCPUとGPUでやらせたときの処理時間比が私のパソコンでは最大180倍になるという結果になった!
これは2^n×2^nの計算領域でCPUとGPUで流体計算させたときの1ループの処理時間(秒)
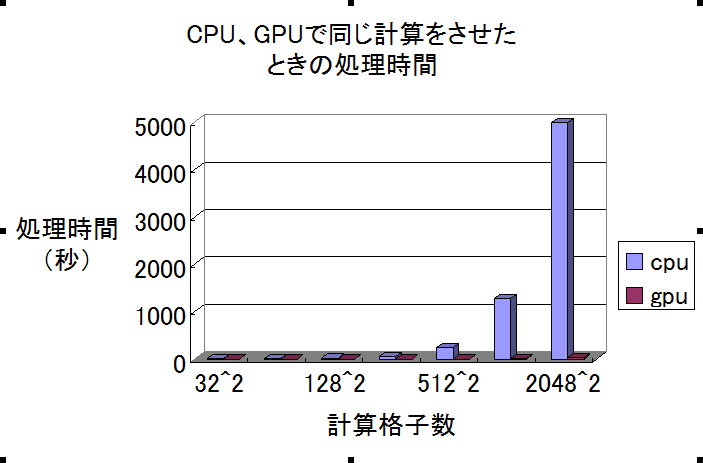
あまりにもGPUの計算時間が早くて、いまいちすごさがパッとしないので処理時間の比をとってみた
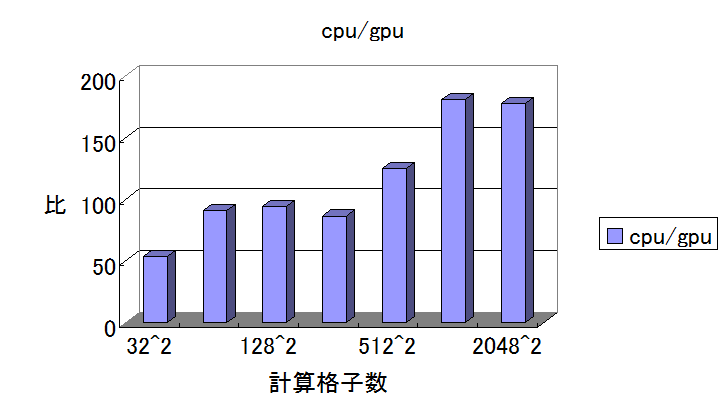
横軸が若干省略されてしまっているが、
512^2と2048^2の間にある1024^2の計算格子領域で一番GPU/CPU比が高く181倍も高速化ができた。
大岡山に存在するとされている某スパコンは、主にこのGPUで計算させているのでCPUのみのスパコンと比べすごく演算が早いとのこと。(もしCPUだけで同じ性能にしようとすると莫大なお金がかかる)
周波数が高いわけではなく、何万もの計算を並列に行なえるから結果的に早いのだそうだ。
・・・さて長い前置きは置いておいて、 私はHSPコンテストで分子シミュレーター
とか
重力シミュレーター

とか
まぁ普通にくだらないクソソフトを毎年量産しては応募しているのだが・・・
何がクソかというと、なんといっても処理が重いのだ!
これはプログラムが非効率なのもあるが、多数の粒子や相互作用などを計算すること自体がそもそも物理的に膨大な計算量を必要とする。
非力な私のノーパソのCPUでは、一億桁×一億桁の計算に何日もかかるというのに、分子のシミュレーションをリアルタイムでやろうとするなんぞ分不相応というか背伸びのしすぎであった・・・
今よりもCPUの性能が上がればいいのだが、生憎CPUのクロック数はもう頭打ちと言われていてせいぜい3.6Ghzが一般CPUの限界だから、今の1.5倍にしかならない。
HSPはマルチスレッド対応ではないため、私のやりたいシミュレーション系のプログラムはもうCPUだけでは限界なのだ。 多重起動の擬似マルチスレッド化とかして工夫はしてきたものやはりCPUに頼っているだけでは根本解決にはならない
そこで、本格的にGPGPUプログラミングに手を出そうと考えていた。
調べていくうちにGPGPUプログラミングのためにはnVIDIA製のGPU搭載デスクトップPCを買い、CUDAを勉強するのが一番手っ取り早いということがわかったのだが・・・
1 買う金がない
2 デスクトップ置く場所がない
3 CUDAを勉強する時間がない
の理由から諦めかけていた。
HSPでGPGPUプログラムができれば全て解決んだけど・・と思って何気なくHSPのサンプルを眺めていたら・・ これはもしかしたら、 HSPでGPGPUぽいことができるんじゃないのかと、そんな確信に近いある予感がひらめいた!!
きっかけはeasy3Dのサンプルのe3dhsp3_CbCr.hspを見た時だった
実行してみると、左には普通の3Dモデルのサンプルがリアルタイムで動いていて、右にはそのモデルの色だけがセピア色に変換されて同じく動いている
そうセピア変換とは、昔私がブログに無駄に長いソースを貼っつけたアレである。
まず画面の全ドットのrgb成分をyuvに逐一変換してuvに一定値を代入してまたrgbに変換・・・というやつである。
これをeasy3Dの中で実現しているということは、GPUにrgbをyuvに変換する並列処理をさせているということに他ならない!(CPUでリアルタイムなんかまず無理であろうし)
ということはソースかdllのプログラムのどこかにこのrgb成分をyuv成分に変換する、掛け、割り、足し、引きの計算式が書かれているはずだ!
そこのソースを改変すれば、自分の好きな手順、順番で四則演算ができるということではないのか!? この仮説が正しければeasy3Dのプラグインを使って高速並列計算が可能ということになる!
高速シミュレーションの道を開くために、執念でdllを解析しようかとか考えていたら、思いのほかもっと近くにその四則演算部分のプログラムを発見した
e3dhsp3.dllのと同じフォルダにある「E3D_HLSL」だ!

そのフォルダにposteffect.fxが入っていて、こいつがセピア変換の四則演算を記述してあるソースだった。
調べたらこの.fxという第二のソースはHLSLといってHigh Level Shader Languageというもうひとつの言語らしい
おや、fxファイルをメモ帳で開くとプログラムソースが見れる!
ということは編集もできるではないか!?
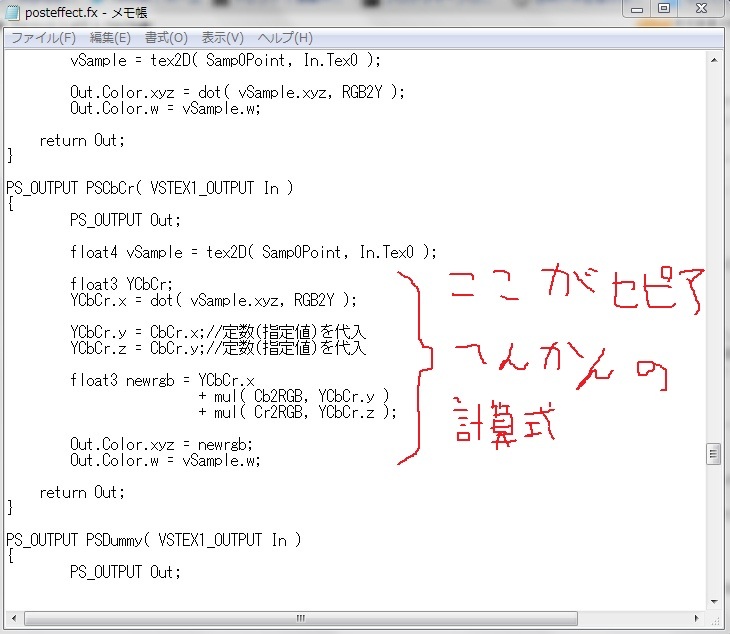
このファイルに自分で式を打って正常に動けば、自分の思い通りの並列処理が可能ってこと!?
試しに計算式を消したり追加したり実験してみたところ、コンパイルが正常に行なわれた
驚くべきことに、HSPで並列処理ができることがこれでわかった!!(正確にはHLSLでだけど・・・)
さらに驚くべきことに、easy3Dのソースを調べていくと律儀にも、私みたいなユーザーがposteffect.fxを改変できるようにと、なんとすでにカスタム領域が備わっていたのだ!
あとからおちゃっこさんのブログを見てわかったのだが「カスタムHLSL機能の需要は?」という名目で2年以上も前にこの自由に定義できるカスタムHLSLの機能を作っていたらしい。
つまりHSP側で並列計算させたいデータをeasy3Dの命令でGPUに送り、GPU側の処理の操作はHLSL(posteffect.fx)のカスタム領域で自分の好きな処理をさせられ、処理結果をまたHSP側で取り出すといった一連の操作が、我々ユーザーのためにすでに可能にされていたということだ。
HLSLのカスタムを可能にしてくれたおちゃっこさんには本当に感謝しないといけない!!
おちゃっこさんは需要なさそうと気にしていらっしゃったようだけど、これぞまさに私の求めていたもの!
この機能に出会えて本当に良かった!
HSPで並列演算ができるとわかった今、シミュレーションプログラムの幅が大きく広がること間違いなしである!!
これでもう数値解析やシミュレーションのデバッグに何日もかけないで済む!
HSPコンテストに糞ソフトと呼ばれるような生半可なシミュレーションソフトは出さないぞ。(呼んでいるのは主に自分)
さらにさらに驚くべきことに自分の非力なノーパにもそれなりのGPU・・オンボードだが・・がそなわっていたらしい!
今の今まで気づかなかった・・そもそもGPUなんて付いてないものかと・・
最大単精度浮動小数点バッファまで対応してるみたいだし、シェーダモデル4.0で、なんだか考えられる中で最高の環境が気づかぬ間に手元にそろっていたようだ。
で、 具体的な並列処理の方法だが、自分の手順をさかのぼってみて、例をおりまぜてまとめてみた。
まずHSP3.2は入っている前提で
・easy3dのサイトからEasy3DForHSP3_ver5233をダウンロードする
・解凍してreadme読む ・readmeの言われたとおりにする
・次に解凍した中のE3D_HLSLのフォルダもhsp3フォルダにコピー
・下のリンクからダウンロードしてきたposteffect.fxを、hsp3フォルダのE3D_HLSLの中にあるposteffect.fxに上書き
いきなりHLSLを自分でカスタムするのは難しいので、他人のカスタムしたものを参考に少しづつ変えて勉強していくのが一番いいだろう。またHLSLのサイトにいけば命令とか演算子が全部見られる。
サンプル 上のサンプルは、左の2枚の画像を加算、減算、割り算、掛け算しその結果を右に出力するというものだ。1~8のキー操作を受け付けて8種類の処理が見れるようになっている。

話を戻して、例えば足し算の並列演算をしたい場合なら、
・#include "e3dhsp3.as"して、E3DCreateRenderTargetTextureで、足す方を格納する2枚のテクスチャと、足した結果を出力するためのテクスチャをひとつ、合計3つ、同じ大きさで作る。
ようはc=a+bという計算をさせたい場合、aというテクスチャとbというテクスチャとcというテクスチャを作ってください、ということだ。
テクスチャの大きさは、並列に処理したい要素数によって変わってくる。65536要素の計算を並列に処理したいときは256*256の大きさのテクスチャをつくればいい。
・E3DShaderConstUserTexで足す2枚のテクスチャをGPUに送る
・E3DCallUserShaderでshadernoを0、passnoを1にして、足し算実行。これでE3DCallUserShaderの描画先のスワップチェインID(テクスチャ)に足し算結果が出力される。(ここらへんはサンプルの中にソースあり)
といった流れが、足し算の並列処理の方法だ。
passnoを変えれば割り算などを指定できる。
当然posteffect.fxを書き換えれば3つ4つ連続の足し算や、割った余りを求めるものなど、無限の処理が可能となる。
出力された計算結果(テクスチャ)はE3DShaderConstUserTexで指定しE3DCallUserShaderでつぎの処理に使いまわしていく事ができる。
上のスクリーンショットにも書いたが、E3DCreateRenderTargetTextureで作成するテクスチャのbit数を16bitや32bitにすれば、浮動小数点同士の足し算掛け算を並列処理できることとなる。
問題は、並列処理するときのデータが全てテクスチャ形式で行なわれているという点である。
はっきりいってHSP側で作ったDOUBLE型の配列変数を浮動小数点テクスチャに変換するというのはかなり至難の業である。(整数テクスチャならば話は簡単で、bmp形式でデータのやりとりを行なえばよい。)
というのもE3DCreateRenderTargetTextureで作ったテクスチャに1ドットずつ特定の値を書き込む命令がない。(というかeasy3Dはおそらくこの使いかたは想定していなかった)。だから何らかの方法で工夫しないといけないのだ。
それに、作れるテクスチャの精度が最大32bitなので標準命令のdoble型(64bit)と比べ精度が落ちる。グラフィックチップによっては16bitが限界だったりするから、CPUでのdoble型の計算をGPUで精度を落とさずやるには、16bitを4回計算みたいな感じでやるなどさらなる工夫が必要となる。
そして浮動小数点テクスチャから配列変数に戻すのも同様に大変である。
そこらへんを考慮した設計でないと、予想と結果が大きく異なってしまう可能性がある。
ということは、HSP側で配列変数を作る必要は本当にあるのかという疑問がわく。
並列演算出力結果を例えば視覚的に見るだけで良い場合(流体解析や分子動力学など)なら、posteffect.fx内で可視化プログラムを作ってしまえば、easy3Dのテクスチャレンダリング命令でスクリーンにいっきに可視化できる。わざわざHSP側で作った配列変数に値を戻さなくても、だ。
理想はそのような形で、最初から最後までテクスチャとして数値を保存しておく方が楽で良いのだが、厳密な数値を文字列として出力しなければいけないなど、どうしてもHSP側の変数に数値を戻す作業が欠かせない場合がでてくるだろう。 浮動小数点バッファを小数のまま保存できたりHSPのメモリに転送できる命令があればいいが、ない以上、1枚の浮動小数点バッファを何枚ものbmpに情報を分解して保存するアルゴリズムを構築するしかないのかもしれない。少なくとも私のお思いつく方法は今のとこそれしかない・・・
それだけがHSPでの並列処理においての大きな問題である。逆にもし単精度浮動小数点テクスチャと標準命令のdouble変数が両方向に対して変換可能になれば、まぁ64→32bitで精度が悪くなるのは仕方ないとして、タイトル通りの「HSPで高速並列演算」が可能になるというわけだ。これからは浮動小数点の構造の勉強をしてなんとか数値の取り込み、取り出しの問題を解決していきたいと思う・・・。
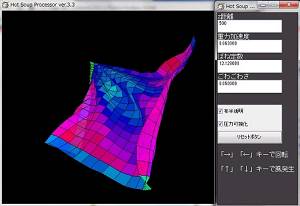
最後に、標準命令だけで作った流体力学プログラムを、HLSLに移植して並列処理化してみた。 計算は32bit浮動小数点バッファを使用、格子数は256*256で、CPUの80倍以上高速に処理できた。
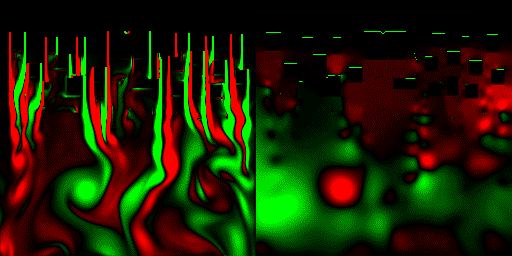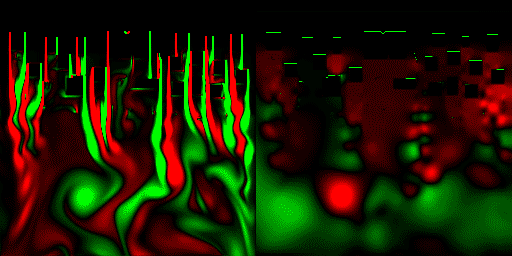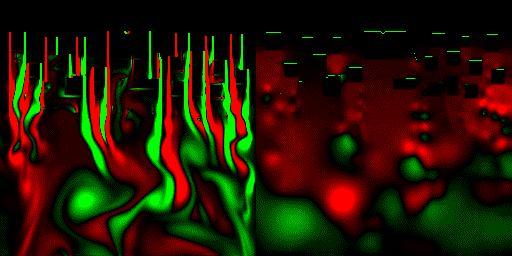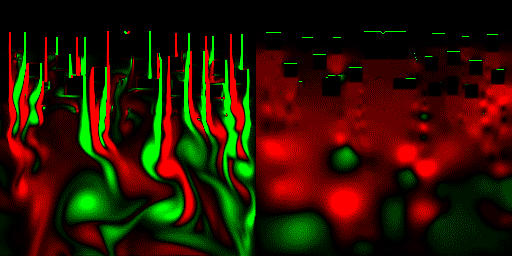
(一応解説すると、上から流体が流れてきてて、画面上の方にあるみにくいけど黒い動かないのが障害物。画面右は圧力を可視化した物。緑=高圧、赤=低圧)
これは、出力がスクリーンのみなので、posteffect.fxのほうに可視化プログラムが記述されており、可視化したテクスチャをeasy3DのE3DRenderSpriteでスクリーンにコピーしている、といったところ。
また入力のほうは、障害物の場所情報とか、0(なし) 1(あり) の2進数で表せるような情報しかないため、HSP側でbmpの生成→easy3Dでbmpの読み込み、bmpをスプライト(整数)に貼りつけ→32bit浮動小数点テクスチャにスプライト貼りつけ、・・と、数値の劣化なくGPUに送ることが出来ている。
並列処理を利用した数値解析シミュレーション特に流体力学はHSPコンテスト2011に向けて温めているもののひとつなのでネタバレはこのくらいにしておくとしよう。
次回:流体力学のプログラムを作りたい!その1
追記
HSP→浮動小数点バッファ への32bit浮動小数のデータ転送は
userFL4_0 ~ userFL4_9 のユーザー定義定数を使って正確に 行なえることが分かった。
また32bit浮動小数点を、4つの8bit*3(r,g,b)バッファに分解して転送して、HLSL側で数値を復元する方法も試みたが、仮数部の最小1bit部分でたまに誤差が生まれる模様・・・
また浮動小数データの分割&整数値化による GPUバッファ→HSP へのデータ転送は全くうまくいかず・・・orz












