







ComputeShaderでAtomic演算
GPUプログラミング(CUDAとかOpenCL)で、GPU上にある配列の総和を求めたいということは良くある。前回shared memoryを使った配列の総和を計算したがこれは良い面も悪い面もある。良い面としては高速なこと、悪い面はややプログラムが煩雑になること。1グループあたり32KBまでしかshared memoryを共有できないため1024要素程度までなら良いが1000万要素もの配列となると入りきらない。
多段式にshared memoryを使ったReductionのコードを組めばそれが最速なのだろうがかなり面倒だ。
そこで、やや速度では劣るが簡便な方法としてAtomic演算を使う。Atomic演算を使うと、変数(アドレス)に対する同時アクセスをスレッド間で排他制御できる。
CUDAでもOpenCLでもAtomic演算はできるし、裏を返せばハードウェア的に、NVIDIA、AMDのGPUでもAtomic演算ができる機能は備わっているはず。どうせ使える機能ならUnityでも使いたい。
実装
例のごとく空のオブジェクトとHost.csとComputeShader.computeを生成してC#(Host.cs)
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using System;
public class Host : MonoBehaviour
{
public ComputeShader shader;
void Start()
{
uint N = 1024;//256の倍数で
uint[] host_B = { 0 };//初期値
ComputeBuffer AtomicBUF = new ComputeBuffer(host_B.Length, sizeof(uint));
int k = shader.FindKernel("sharedmem_samp1");
AtomicBUF.SetData(host_B);
//時間測定開始
int time = Gettime();
//引数をセット
shader.SetBuffer(k, "atmicBUF", AtomicBUF);
//初回カーネル起動
Debug.Log("初回カーネル起動前" + (Gettime() - time));
shader.Dispatch(k, (int)N/256, 1, 1);
Debug.Log("初回カーネルDispatch後 " + (Gettime() - time));
AtomicBUF.GetData(host_B);
Debug.Log("初回カーネルGetData直後 " + (Gettime() - time));
// こっちが本命。GPUで計算
host_B[0] = 0;
AtomicBUF.SetData(host_B);
shader.Dispatch(k, (int)N/256, 1, 1);
Debug.Log("本命カーネルDispatch直後 " + (Gettime() - time));
// device to host
AtomicBUF.GetData(host_B);
//結果
Debug.Log("本命カーネル確定終了 " + (Gettime() - time));
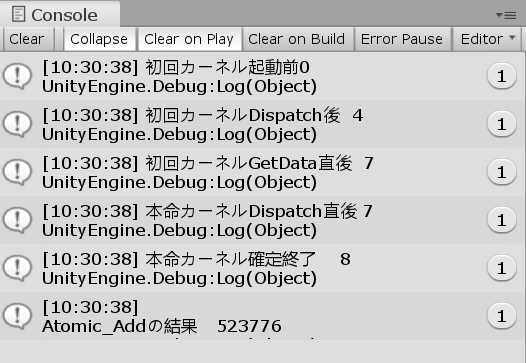
Debug.Log("\nAtomic_Addの結果 "+host_B[0]);
//解放
AtomicBUF.Release();
}
// Update is called once per frame
void Update()
{
}
//現在の時刻をms単位で取得
int Gettime()
{
return DateTime.Now.Millisecond + DateTime.Now.Second * 1000
+ DateTime.Now.Minute * 60 * 1000 + DateTime.Now.Hour * 60 * 60 * 1000;
}
}ComputeShader(ComputeShader.compute)
#pragma kernel sharedmem_samp1 RWStructuredBuffer<uint>atmicBUF;//1要素 [numthreads(256, 1, 1)] void sharedmem_samp1(uint id : SV_DispatchThreadID) { InterlockedAdd(atmicBUF[0], id); }
https://github.com/toropippi/Uinty_GPGPU_SharedMem_AtomicAdd/tree/master/gpgpu_sample4
0~N-1までの総和を求めることができた。
(計算時間を測定するのがくせなので初回カーネルとか書いてあるが今回はあまり重要ではない)
計算速度について
基本的にはAtomic演算はShared memoryを使った方式よりかなり遅いと思っていたほうが良い。グローバルメモリに対してGPU全コアから排他制御でアクセスしているのでランダムアクセスみたいな遅さになる。ハイブリッドな方法として、shared memoryで1グループ内で総和を求めた後、その値をAtomic演算で総和していくのがプログラムを書く上でも簡単で良いかなと私は考えている。
他の演算
今回のは32bit整数型のAtomic演算のaddを使ったサンプルになる。ほかにも引き算やビット演算などAtomic演算はいくつもある。以下を参照のことInterlockedXor
なお、この中に32bit浮動小数点数に対するAtomic演算は含まれておらず、いわゆるFloat型の総和を求めたいときはAtomic演算でなくShared memoryを使うしかない。なぜかはわからないが、CUDAのみFloat型に対してもAtomic演算を行なう機能を持っており、Compute ShaderやOpenCLにはその機能がない。(非正規化数周りとかを異なるGPUベンダー間で統一できないからか?)
「OpenCL float atomic add」などで調べるとCompareExchange演算を使って無理やりfloatの加算を実現してるコードなども出てくるが、やや効率は落ちるようだ。
※本ブログで紹介しているソースコードはすべてCC0 パブリックドメインです。
ご自由にお使いください
なお、この中に32bit浮動小数点数に対するAtomic演算は含まれておらず、いわゆるFloat型の総和を求めたいときはAtomic演算でなくShared memoryを使うしかない。なぜかはわからないが、CUDAのみFloat型に対してもAtomic演算を行なう機能を持っており、Compute ShaderやOpenCLにはその機能がない。(非正規化数周りとかを異なるGPUベンダー間で統一できないからか?)
「OpenCL float atomic add」などで調べるとCompareExchange演算を使って無理やりfloatの加算を実現してるコードなども出てくるが、やや効率は落ちるようだ。
※本ブログで紹介しているソースコードはすべてCC0 パブリックドメインです。
ご自由にお使いください
前
次










