





Failed to present D3D11 swapchain due to device reset/removed.
というエラーメッセージについて、個人的にハマったこと、解決したことをまとめようと思います。結論から言うとこういうことです。
環境:Windows 11、Unity 2021.2.7f1、GPUはGeForce MX150(mem 2GB)
・Windowsで描画担当のGPUが高負荷で数秒応答しなくなった時、ドライバが強制終了する仕様がある
・Unityのプログラムで初期地形生成にGPUのComputeShaderを使っていた。低スペックGPUだと3-5秒くらいかかるので、タイムアウト時間によりOSがドライバをリセット、Unityで上記エラーが発生
さて、これはバグでもなくUnity側の不具合でもなく、WindowsOSの仕様が引き起こしたことなのでバグとは呼ばず「エラー」と言うこととします。
では時系列順に起こったことを書いていきます。
Unity Editorでエラー&強制終了
ある日からUnity Editorで再生ボタンを押すとこのようにエラーマークが出てEditorごと落ちるようになった。
100%落ちるわけではなく20%くらいの確率で普通にうまくプログラムが起動する。
また、別の高スペックなほうのPCでやると一切エラーマークは発生せず、ちゃんと起動する。
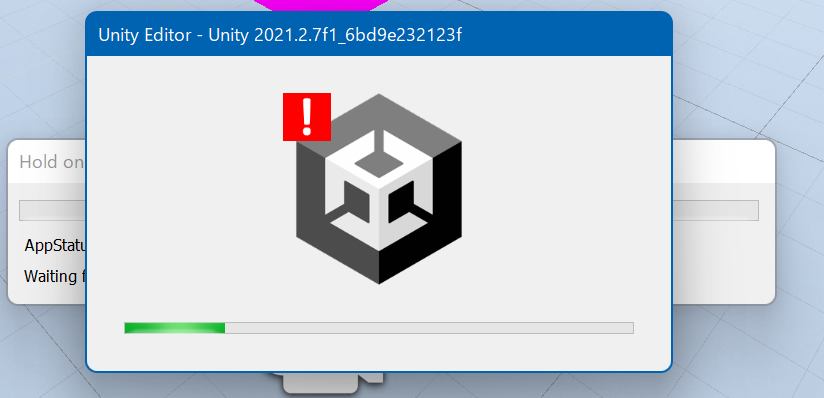
Unity側からしてみると、プログラム実行中にドライバが突然リセットされるので何が起こったかわかるはずもありません。最初まともなエラーメッセージがでなかったのも無理はありません。
多分、WindowsOSがGPUドライバを強制リセットすることがあるということを知らないとなかなか解決には至らなかったかと思うので今回記事にさせていただきました。
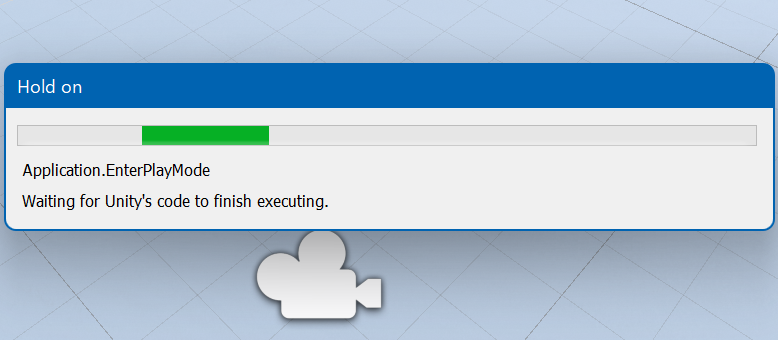
Waiting for Unity's code to finish executing
続いてエラーが出るときにEditor Windowの後ろのほうに出ているメッセージになにかヒントがないか調べてみた。
"EnterPlayMode"や"Waiting for Unity's code to finish executing"などで検索するも有益な情報なし。
そもそも今回のエラーと関係あるのか確証もなかった。
Buildしたらどうなるか
Editor上で実行するときだけ起こる問題なのかと思い、今度はBuildでexeを生成してから実行してみた。
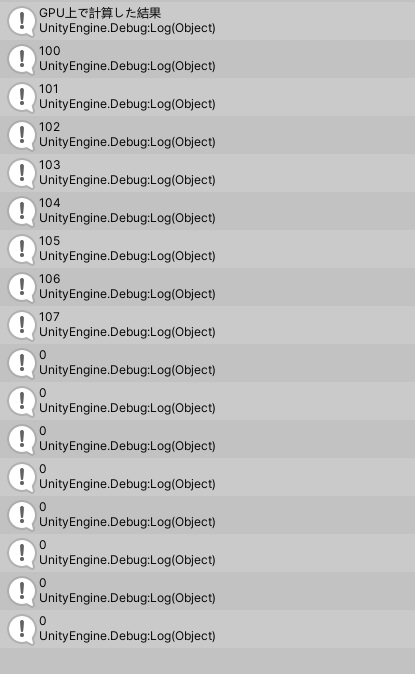
すると100%の確率で強制終了。画像のようなエラーマークがでる。
別のPCでやるとちゃんと起動できる。なのでPCのスペックに依存したエラーかなとあたりがつく

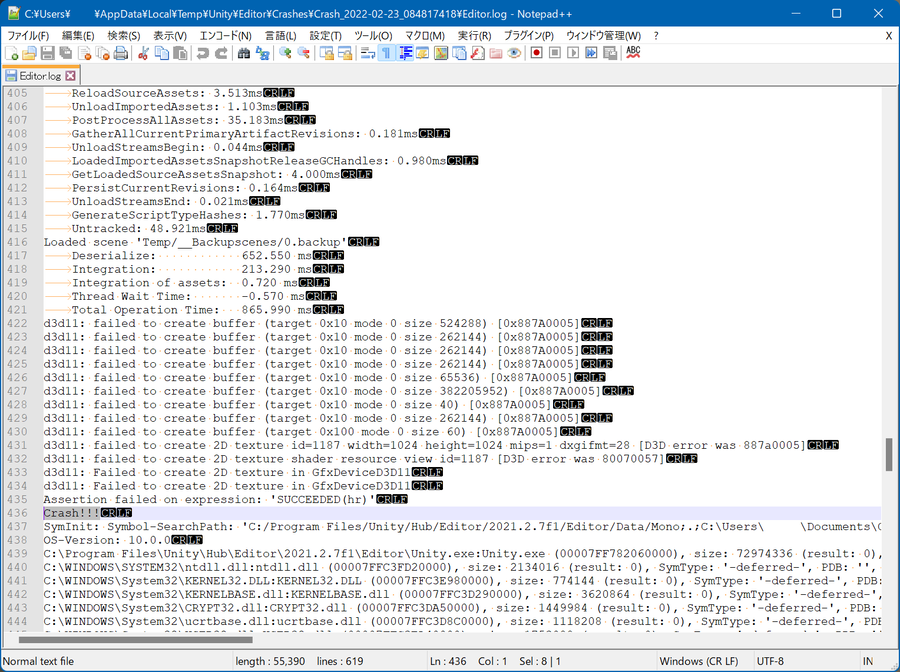
クラッシュログを見る
Editorでエラー終了するときにどうもクラッシュログが生成されていることに気づく。
クラッシュログをみるとGPUのメモリ確保(TextureやComputeBuffer)に全て失敗しているようだった。
これでGPU関連のプログラムでなにかまずいことをしているかもと絞り込んでいろいろ試行錯誤開始。
エラーが発生しない状況を突き止める
その結果、地形生成部分のGPUの計算負荷(ComputeShaderを使っている)を軽くするとエラーが発生しないことがわかった。具体的には1616×1616マスの地形生成を208×208に減らした。
なので今後は1616×1616のうち208×208の地形生成を最初に行い、数秒後に残りの部分の地形生成を行いエラーが発生するか確かめてみることにした。
GPU Timeoutの原因がexpensive workloads
そうしたところエラー発生。ついに有益なメッセージが得られた。
Failed to present D3D11 swapchain due to device reset/removed.
This error can happen if you draw or dispatch very expensive workloads to the GPU,
which can cause Windows to detect a GPU Timeout and reset the device.
which can cause Windows to detect a GPU Timeout and reset the device.
~~~~~~~~~

要約するとGPU負荷がすごすぎてGPUタイムアウト、Windowsがデバイスをリセットした、ということのよう。
これはWindows上でCUDAで遊んだり機械学習してる人なら見慣れている光景かもしれないが、レジストリのTdrDelayを書き換えれば解決するやつ。
TdrDelayを書き換え解決
リンクのやつを参考にTdrDelayを60秒にして再起動をかける。
これでついにUnity Editorと.exe両方でエラーが発生しなくなった!
http://www.slis.tsukuba.ac.jp/~fujisawa.makoto.fu/cgi-bin/wiki/index.php?CUDA%A5%AB%A1%BC%A5%CD%A5%EB%BC%C2%B9%D4%A4%CE%A5%BF%A5%A4%A5%E0%A5%A2%A5%A6%A5%C8
http://www.slis.tsukuba.ac.jp/~fujisawa.makoto.fu/cgi-bin/wiki/index.php?CUDA%A5%AB%A1%BC%A5%CD%A5%EB%BC%C2%B9%D4%A4%CE%A5%BF%A5%A4%A5%E0%A5%A2%A5%A6%A5%C8
振り返り
振り返ってみると、ある日からエラーが発生するようになったのはWindows 11にアップデートしたからでした。もともとWindows10で作業していたときは別件ですでに上記のレジストリをいじっていたのでエラーは発生しなかったのだと思われます。これがOSアップデートで戻され、タイムアウト時間が数秒程度になっていたのでしょう。Unity側からしてみると、プログラム実行中にドライバが突然リセットされるので何が起こったかわかるはずもありません。最初まともなエラーメッセージがでなかったのも無理はありません。
多分、WindowsOSがGPUドライバを強制リセットすることがあるということを知らないとなかなか解決には至らなかったかと思うので今回記事にさせていただきました。
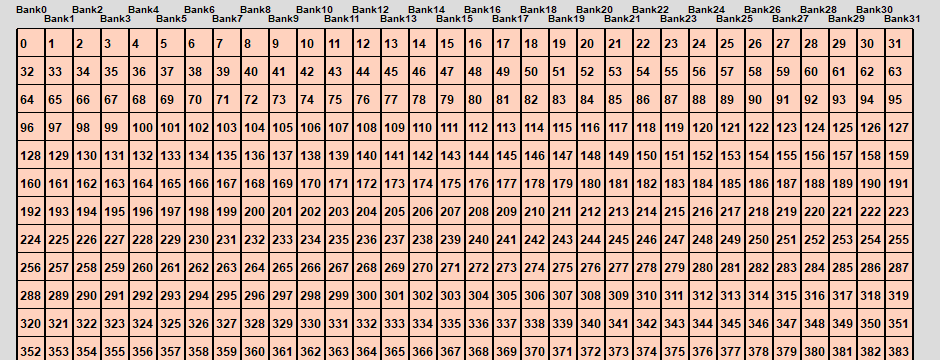
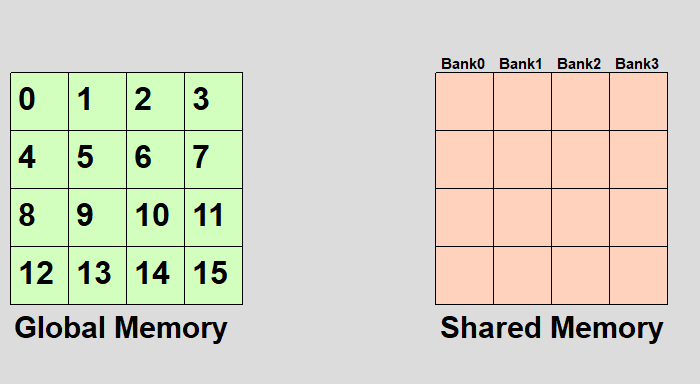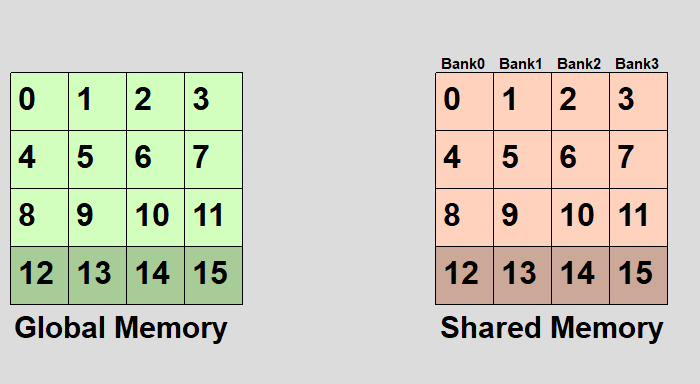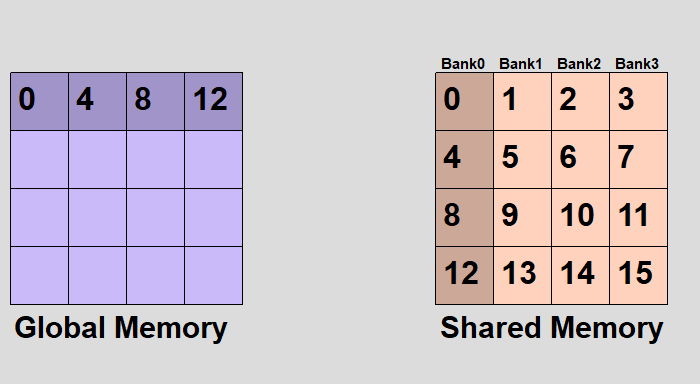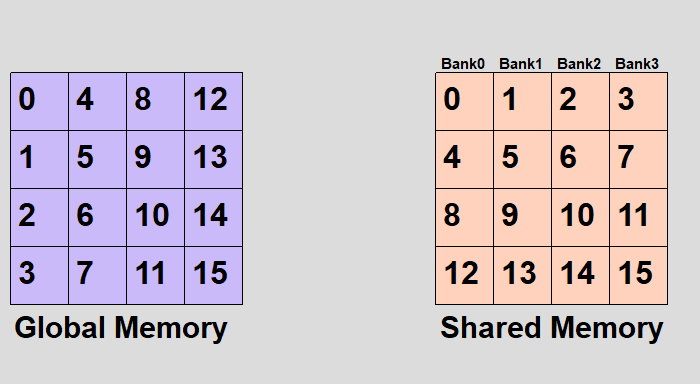

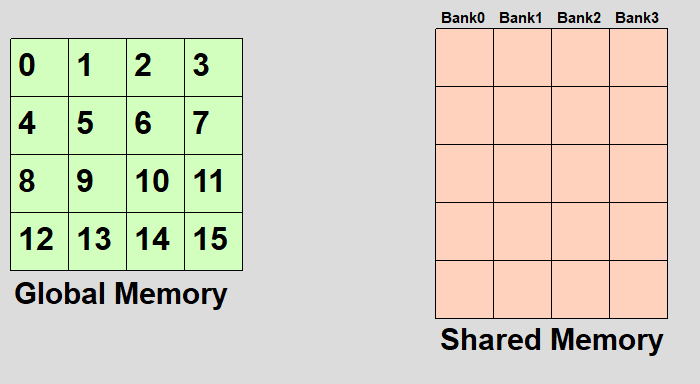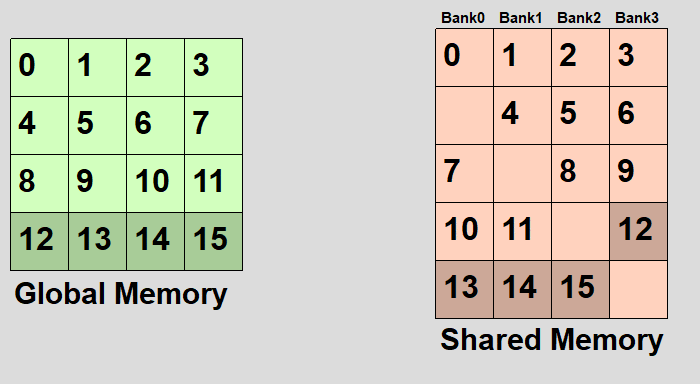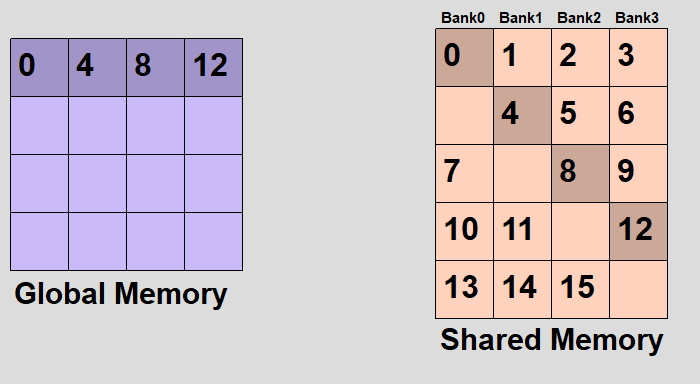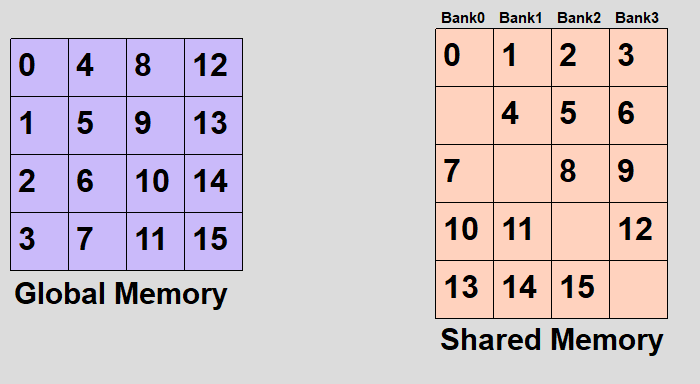
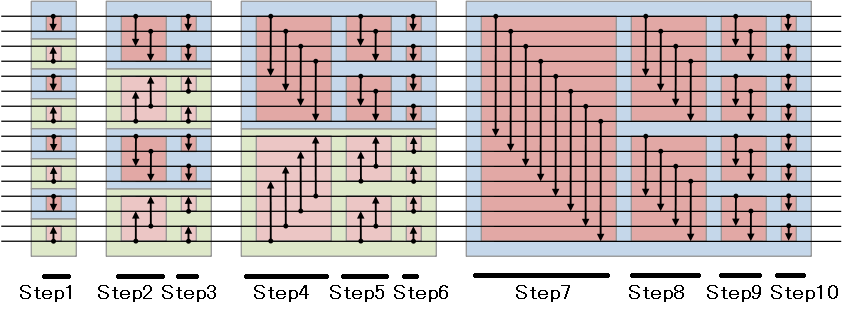
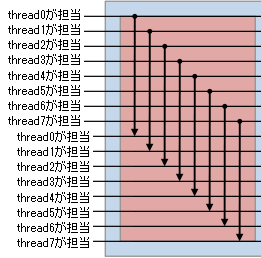
 とりあえず英語のwikipediaの画像がわかりやすいので転載してみた。
とりあえず英語のwikipediaの画像がわかりやすいので転載してみた。